以下為25個國家,其國民於9大類食物之蛋白質消耗統計表。若依9大類食物其蛋白質消耗情形類似國家為樹形圖繪製依據,須如何評估及執行?

將數據打入sas中
data Protein;
length country $14;
input Country $ RedMeat WhiteMeat Eggs Milk Fish Cereal Starch Nuts FruitVeg;
datalines;
Albania 10.1 1.4 0.5 8.9 0.2 42.3 0.6 5.5 1.7
Austria 8.9 14.0 4.3 19.9 2.1 28.0 3.6 1.3 4.3
Belgium 13.5 9.3 4.1 17.5 4.5 26.6 5.7 2.1 4.0
Bulgaria 7.8 6.0 1.6 8.3 1.2 56.7 1.1 3.7 4.2
Czechoslovakia 9.7 11.4 2.8 12.5 2.0 34.3 5.0 1.1 4.0
Denmark 10.6 10.8 3.7 25.0 9.9 21.9 4.8 0.7 2.4
E_Germany 8.4 11.6 3.7 11.1 5.4 24.6 6.5 0.8 3.6
Finland 9.5 4.9 2.7 33.7 5.8 26.3 5.1 1.0 1.4
France 18.0 9.9 3.3 19.5 5.7 28.1 4.8 2.4 6.5
Greece 10.2 3.0 2.8 17.6 5.9 41.7 2.2 7.8 6.5
Hungary 5.3 12.4 2.9 9.7 0.3 40.1 4.0 5.4 4.2
Ireland 13.9 10.0 4.7 25.8 2.2 24.0 6.2 1.6 2.9
Italy 9.0 5.1 2.9 13.7 3.4 36.8 2.1 4.3 6.7
Netherlands 9.5 13.6 3.6 23.4 2.5 22.4 4.2 1.8 3.7
Norway 9.4 4.7 2.7 23.3 9.7 23.0 4.6 1.6 2.7
Poland 6.9 10.2 2.7 19.3 3.0 36.1 5.9 2.0 6.6
Portugal 6.2 3.7 1.1 4.9 14.2 27.0 5.9 4.7 7.9
Romania 6.2 6.3 1.5 11.1 1.0 49.6 3.1 5.3 2.8
Spain 7.1 3.4 3.1 8.6 7.0 29.2 5.7 5.9 7.2
Sweden 9.9 7.8 3.5 4.7 7.5 19.5 3.7 1.4 2.0
Switzerland 13.1 10.1 3.1 23.8 2.3 25.6 2.8 2.4 4.9
UK 17.4 5.7 4.7 20.6 4.3 24.3 4.7 3.4 3.3
USSR 9.3 4.6 2.1 16.6 3.0 43.6 6.4 3.4 2.9
W_Germany 11.4 12.5 4.1 18.8 3.4 18.6 5.2 1.5 3.8
Yugoslavia 4.4 5.0 1.2 9.5 0.6 55.9 3.0 5.7 3.2
;
proc cluster data=protein method=Ward plots=dendrogram(height=rsq) ccc pseudo;
id Country;
run;
proc cluster以凝聚方法(即由多類降至少類)執行分層聚類(此處版大使用ward最小變異數法)進而繪製出樹狀圖,此處樹的高度指定為rsq,即R-squared.
height=可以接height (半偏R平方),mode(嘿嘿嘿,用下去你就知,可看日誌),ncl(群集數),rsq(R-squared)
另外,可限制群組數上限,若只想顯示20組,則於proc cluster 後加入print=20
由下面說明,可以知道也能用簡稱字母取代全銜。

R平方:愈大表示類與類之間區分的愈開,聚類效果愈好(反之,該變項其R平方若小很多,在分群時不須考慮它,它對分群沒有貢獻)。但不能單看此R-squared, 也應看此步的R-squared與上一步R-squared的差值,此概念即半偏R平方。
半偏R平方:愈大說明本次合併的效果不佳,應當考慮聚類到上一步就停。
虛擬F統計:該值愈大表示分類效果愈好。
虛擬T平方:在此處有太多的缺失值。故不要看,若不想讓它出現在下下圖中,可將語法改成如下:
proc cluster data=distdcorr method=ward pseudo plots(only)=(psf dendrogram);
id company;
run;

當群組數由1進入2時,R平方由0變為0.495,增幅為0.495
當群組數由2進入3時,R平方由0.495變為0.655,增幅為0.160,增幅的概念即為旁邊欄的半偏R平方,當增幅明顯變小時,表示該停止分類了。故此案版大決定只分出4個群組。


表示依「25個國家,國民於9大類食物之蛋白質消耗統計表」,可將其分為4個群組,群組內的國家表示消耗性類似。
可再透過proc fastclus執行「K平均值演算法」呈現進一步數據。
proc fastclus data=protein maxc=4 out=clus;
id country;
var RedMeat WhiteMeat Eggs Milk Fish Cereal Starch Nuts FruitVeg;
run;
maxc=4直接讓群集數=4 將所有統計過程及結果產生的數據寫入clus資料集中,以便後續將分類成果匯出且轉成excel檔。
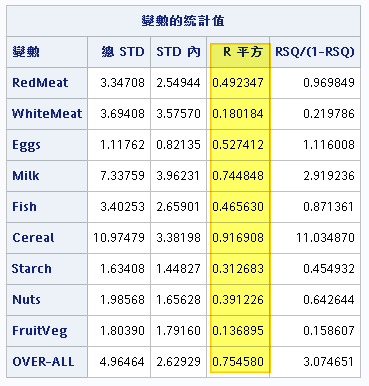
每一群集其中心落點

RMS標準差愈小,表示群組內的國家彼此間的相似性很高。

R平方表示該變項對分群的貢獻性,愈小則貢獻性愈低。如whitemeat和fruitveg,其分群的貢獻就很低。
資料集clus全部內容

若須調整樹形圖格式(軸名稱、字大小、數字間距等),於proc cluster 後加入 outtree=kkk;
再拿此資料集來畫樹狀圖。
資料集kkk全貌

axis1 order=(0 to 25 by 1) value=(h=1.2)label=(h=1.4);
axis2 value=(h=1.2);
proc tree data=kkk haxis=axis1 vaxis=axis2 horizontal;
height _ncl_; /*將x軸改成群集數*/
id country;
run;

注意,這種格式調整法屬較舊程式(有別於proc sgplot, proc sgpanel等),於免費SAS中不支援。
另外,也可於SAS Enterprise Guide透過對話視窗點按操作。

SAS官方釋出的教學影片
若要客製化樹形圖,請於下圖中黃底處拖入id變項(此案為country)。
否則使用proc tree時,資料集內將無id變項可放。

https://support.sas.com/documentation/onlinedoc/stat/131/distance.pdf
https://documentation.sas.com/?docsetId=statug&docsetTarget=statug_cluster_syntax01.htm&docsetVersion=15.1&locale=en
如果本文章提供的資訊對你有幫助,可以考慮請我喝飲料(金額隨喜),謝謝。
台新銀行帳戶 (備註: SAS5)

沒有留言:
張貼留言